Dongqi Liu
My name in Oracle Bone Script:
Doctoral researcher in Computational Linguistics
Campus C7.2, Saarland University, 66123, Germany
dongqi.me [AT] gmail.com
![]()
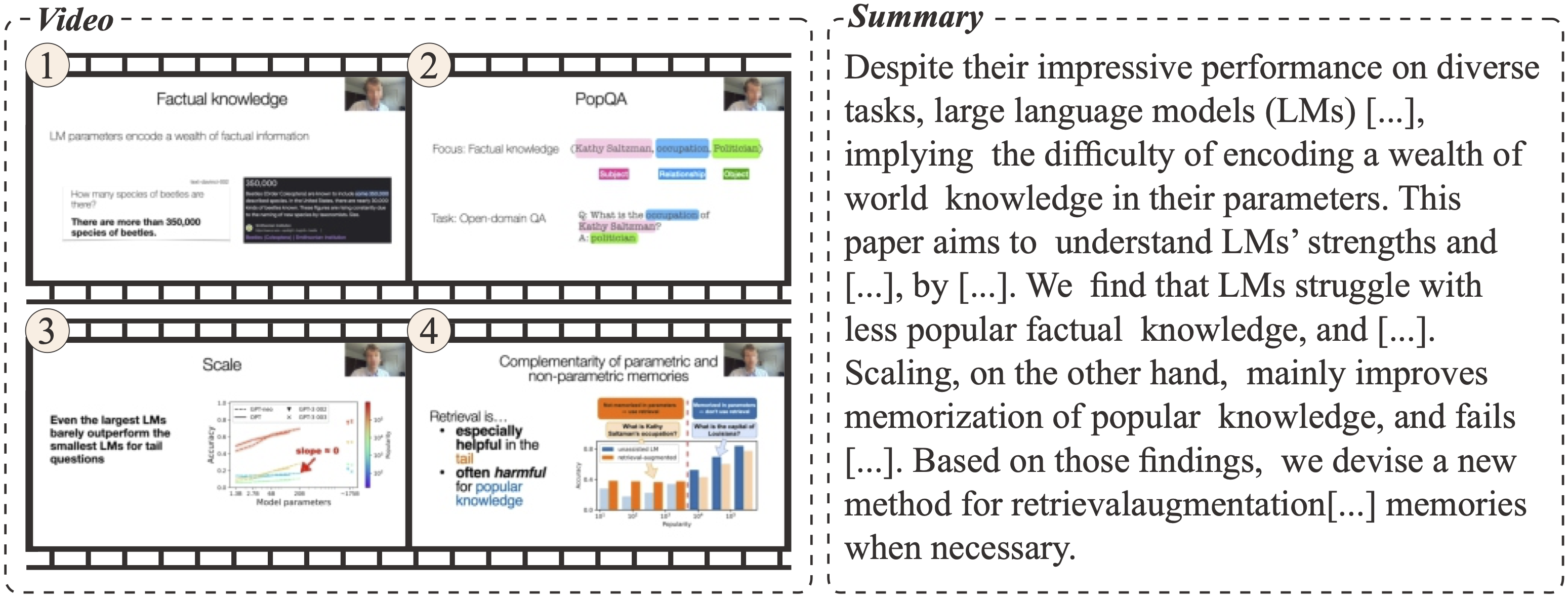
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
📄 Abstract
Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of our dataset. This study aims to pave the way for future research on scientific video-to-text summarization.
🔍 Overview
💻 Code
Our code is publicly available on GitHub:
📊 Dataset
The VISTA dataset is available on Huggingface:
📚 Citation
@article{liu2025vista, title={What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations}, author={Liu, Dongqi and Whitehouse, Chenxi and Yu, Xi and Mahon, Louis and Saxena, Rohit and Zhao, Zheng and Qiu, Yifu and Lapata, Mirella and Demberg, Vera}, booktitle={Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, year={2025} }